データセットおよびSPARQLクエリサービスの利用方法
メディア芸術データベースのデータ構成について
メディア芸術データベースのデータセットは、Linked Open Dataに対応した形式であるResource Description Framework(RDF)で記述されます。ここではデータの基本的な構造を概説します。より詳細なデータセットのメタデータスキーマについては MADBメタデータスキーマ仕様書をご参照ください。
メディア芸術データベースは、メディア芸術(ここではマンガ・アニメーション・ゲーム・メディアアートの4分野を指す)作品やその資料、所蔵情報などの対象物に関する情報を提供しています。本データセットでは、こうした提供する情報の記述対象をリソースと呼び、固有のIDに基づくURIを用いて記述しています。
メディア芸術データベースのデータモデルでは、作品を体現する資料を表す「アイテム」、アイテムの集合を表す「コレクション」という分類でリソースを整理しています。また、RDFでは同種のリソースが共通して備える特徴に基づき抽象化した概念をクラスと呼びます。本データセットのメタデータスキーマでは、アイテムをItemクラス、同一分野のアイテムのみで構成されるコレクションをCollectionクラス、複数の分野のアイテムで構成されるコレクションをCurationクラスとして定義しています。
マンガ分野のリソースを記述したデータの例を以下に図示します。リソースが属するクラスは rdf:type というプロパティで記述されています。この図に記述されたプロパティrdf:typeを確認すると、あるマンガ単行本を表すアイテムのリソースと、そのコレクションであるリソースが存在することが分かります。これら2つのリソースの関係は schema:isPartOf というプロパティで記述されます。また、このアイテムのリソースの所蔵情報は schema:provider というプロパティに入れ子の構造で記述されます。
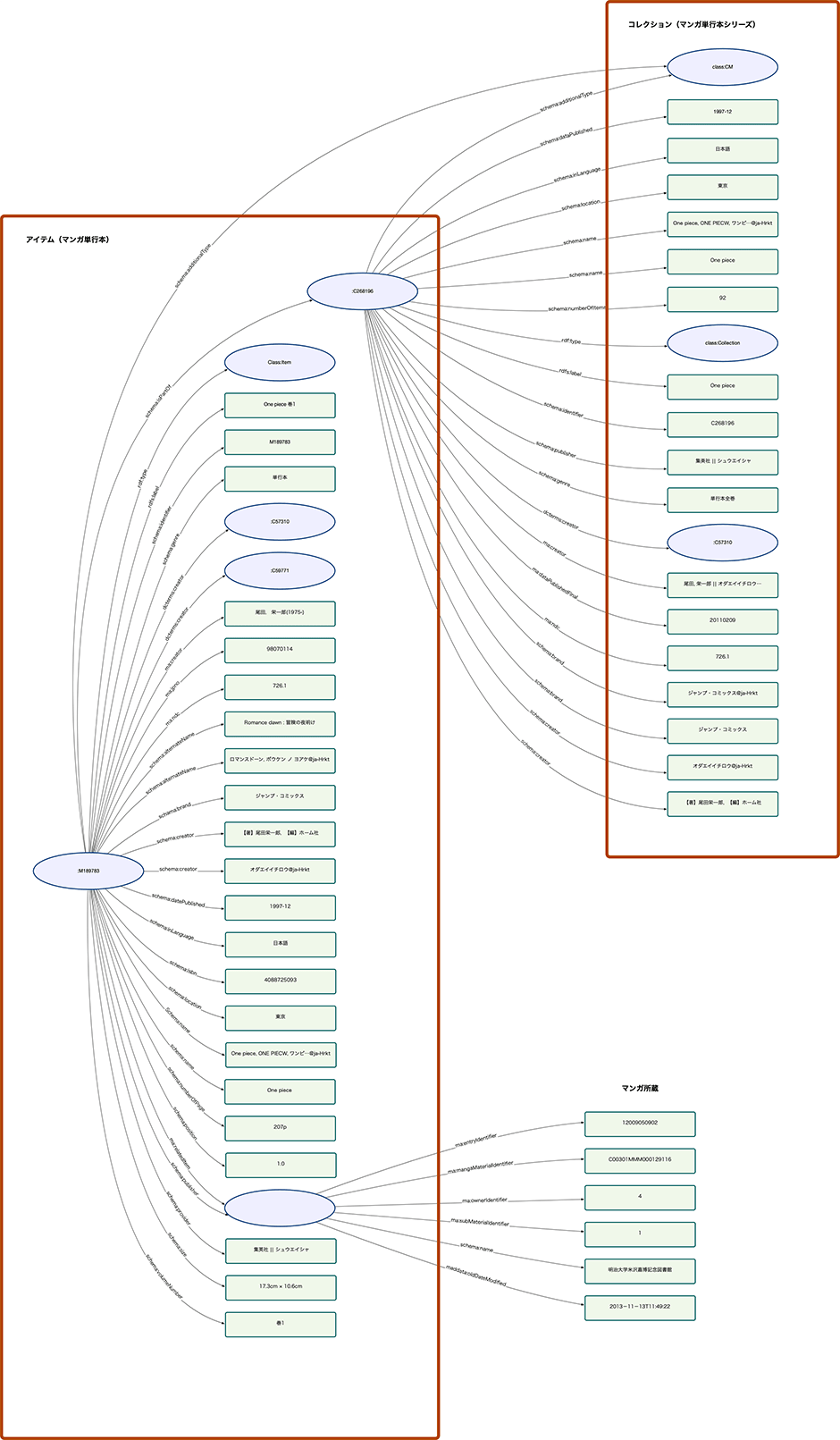
リソースのURI
ItemクラスやCollectionクラス、Curationクラスのリソースには、https://mediaarts-db.artmuseums.go.jp/id/ にメディア芸術データベースID(MADB ID)の組み合わせで生成される一意なURIが与えられています。
MADB IDは、ItemクラスのリソースにはM+連番、Collectionクラス、CurationクラスのリソースにはC+連番の規則に従って付与されています。
所蔵情報などのSupplementクラスのリソースにはS+連番の規則でMADB IDが付与されていますが、IDの永続性を担保しないリソースであるため、名前空間を https://mediaarts-db.artmuseums.go.jp/ref/ に切り分けています。
データセットで使用する語彙
メディア芸術データベースのデータセットでは、Schema.orgやDCMI Metadata Termsなどの国際的に標準として用いられる語彙のほか、独自に定義する以下の語彙を使用します。
| 語彙 | 名前空間名 | 接頭辞 |
|---|---|---|
| MADBMS独自語彙(クラス) | https://mediaarts-db.artmuseums.go.jp/data/class# | class: |
| MADBMS独自語彙(プロパティ) | https://mediaarts-db.artmuseums.go.jp/data/property# | ma: |
Turtle形式:
メディア芸術データベースが提供しているデータについて
データセット
メディア芸術データベースでは、公開する全データをファイルとして公開・提供しています。このデータセットはウェブ上でデータを共有するための技術標準であるLinked Open Dataに対応した形式で記述され、誰でも自由に利用できます。ウェブサイト・ウェブAPIでは提供していない複雑な検索を御自身で行える他、他のデータベースとリンクさせて組み合わせて利用することが可能です。また、御自身で開発されるサービスに組み込んで御活用いただけます。
データセットの仕様や詳細についてはメディア芸術データベースのメタデータスキーマとして提供されています。
データセット・メタデータスキーマはダウンロードページよりダウンロードいただけます。
SPARQL エンドポイント
使い方まず、リソースのジャンルを示すプロパティschema:genre を用いて簡単なクエリを実行してみます。クエリ 1は、ジャンルが「マンガ雑誌単号」であるリソースを取得するクエリです。変数 ?アイテム に当該リソースのURIがバインドされ、クエリの結果として得られます。また、プロパティrdfs:label を用いて人間が識別するための名称を同時に取得しています。
クエリ1
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX schema: <https://schema.org/>
PREFIX ma: <https://mediaarts-db.artmuseums.go.jp/data/property#>
SELECT ?アイテム ?ラベル
WHERE {
?アイテム schema:genre "マンガ雑誌単号" ;
rdfs:label ?ラベル .
}
LIMIT 1000
クエリ2では、あるマンガ雑誌単号について、その内容細目(いわゆる目次)の情報を開始ページやサブタイトルなどの記述項目のセットとして取得し、ORDER BY句を用いて開始ページの小さい順にソートしています。
クエリ2
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX schema: <https://schema.org/>
PREFIX ma: <https://mediaarts-db.artmuseums.go.jp/data/property#>
PREFIX class: <https://mediaarts-db.artmuseums.go.jp/data/class#>
SELECT
?マンガ雑誌単号ラベル ?開始ページ ?終了ページ ?分類・記事種別 ?タイトル
WHERE {
<https://mediaarts-db.artmuseums.go.jp/id/M535428> a class:MangaMagazineIssue ;
schema:genre "マンガ雑誌単号" ;
rdfs:label ?マンガ雑誌単号ラベル ;
schema:hasPart [
schema:genre ?分類・記事種別 ;
schema:pageStart ?開始ページ ;
schema:pageEnd ?終了ページ ;
schema:alternativeHeadline ?タイトル ;
].
}
ORDER BY xsd:float(?開始ページ)
SPARQLでは、1つのクエリの中で他のSPARQLエンドポイントに対してクエリを実行することができます。つまり、複数のSPARQLエンドポイントに存在するデータをつなげた結果を得ることができます。このようなクエリをフェデレーテッドクエリ(federated query)と呼び、本エンドポイントは フェデレーテッドクエリhttps://www.w3.org/TR/2013/REC-sparql11-federated-query-20130321/に対応しています。
例えばクエリ 3では、メディア芸術データベースのリソースURIをもとに、SERVICE句で指定したWikidataのSPARQLエンドポイントに対してそのリソースのタイトルを取得するクエリを実行しています。Wikidataでは様々な言語で記述されたタイトルのデータが提供されており、このクエリではそれらをまとめて取得することができます。LANG(?タイトル)は、?タイトル の言語タグを取得するための記述です。
クエリ3
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX schema: <https://schema.org/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
SELECT
?wikidataEntity ?タイトル (LANG(?タイトル) AS ?言語タグ)
WHERE {
# 例: アニメ映画シリーズ「君の名は。 your name.」
<https://mediaarts-db.artmuseums.go.jp/id/C413599> schema:identifier ?メディア芸術データベースID .
SERVICE <https://query.wikidata.org/sparql> {
# wdt:P7886 はWikidataでメディア芸術データベースのID(URI)を示すプロパティ
?wikidataEntity wdt:P7886 ?メディア芸術データベースID ;
rdfs:label ?タイトル .
}
}
全文検索
本SPARQLエンドポイントは、Amazon Neptuneの拡張機能を利用した全文検索クエリに対応しています。以下の全文検索用パラメータをSERVICE句を用いて指定することで実行できます。
| プロパティ | 値 |
|---|---|
| neptune-fts:endpoint | "https://vpc-mediaarts-db-qaymrmtqbprlhmqq33a2ncf4ke.ap-northeast-1.es.amazonaws.com" |
| neptune-fts:queryType | 全文検索のクエリ種別。次のいずれか1つを指定します。 "simple_query_string", "match", "prefix", "fuzzy", "term", "query_string" |
| neptune-fts:query | 実行するクエリ文字列。 |
| neptune-fts:field | 検索対象のプロパティ。 |
| neptune-fts:maxResults | 検索結果の最大取得数。省略時は10,000になります。 |
| neptune-fts:return | 検索結果のリソースのURIがバインドされる変数。 |
- 接頭辞「neptune-fts:」は名前空間名「 http://aws.amazon.com/neptune/vocab/v01/services/fts#」を表します。
- SERVICE句のエンドポイントには neptune-fts:search を指定します。
- いずれも主語は neptune-fts:config を指定します。
- 各パラメータの仕様の詳細はAmazon Neptuneの資料をご参照ください。
https://docs.aws.amazon.com/neptune/latest/userguide/full-text-search-parameters.html
クエリ4では、ラベルに「魔法」と「戦」の両方を含むリソースを取得する全文検索クエリを実行しています。クエリ種別 query_string は、ANDやORなどの演算子を含む構文を使うことで、より複雑な検索条件を指定することができます。
クエリ4
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX schema: <https://schema.org/>
PREFIX neptune-fts: <http://aws.amazon.com/neptune/vocab/v01/services/fts#>
SELECT ?リソース ?ジャンル ?ラベル
WHERE {
SERVICE neptune-fts:search {
neptune-fts:config neptune-fts:endpoint "https://vpc-mediaarts-db-qaymrmtqbprlhmqq33a2ncf4ke.ap-northeast-1.es.amazonaws.com" .
neptune-fts:config neptune-fts:field rdfs:label .
neptune-fts:config neptune-fts:queryType "query_string" .
neptune-fts:config neptune-fts:query '\"魔法\" AND \"戦\"' .
neptune-fts:config neptune-fts:return ?リソース .
}
?リソース schema:genre ?ジャンル ;
rdfs:label ?ラベル .
}
制限
- リクエスト推定実行時間が60秒を超えることが想定される場合、エラーメッセージを表示します。
- 同じIPアドレスから短時間で連続的な呼び出しを検知した場合、そのIPアドレスからの接続を一時的に遮断する場合があります。
- 主語が空白ノードであるリソースは全文検索の対象にはなりません。