メディア芸術データベースでは、外部のデータセットとの連携活動の一つとして、Wikidata(ウィキデータ)とのデータ連携の強化を試みています。調査レポート「Wikidataとのデータ連携、その現況と展望」では、メディア芸術データベースとWikidataとの連携状況やその意義が述べられています。Wikidataとの連携は、メディア芸術データベースのリソースのID(MADB ID)をWikidataのリソースのプロパティ「メディア芸術データベース識別子」によってリンクすることで実現されますが、まだその数は十分とは言えません。Wikidataのウィキデータ項目ページからメディア芸術データベース識別子を一つ一つ編集していくことでリンクを作ることができますが、本レポートではMix’n’matchというツールを用いてより効率的にリンクを作るための取り組みを紹介します。
Mix’n’matchとは
Mix’n’matchとは、Wikidataとリンクさせたい他のデータセットとのマッチング作業を支援するツールです。リンクさせたいデータセットを「カタログ」として登録することで、そのカタログに含まれるリソースと一致するWikidataのリソースの候補を自動的に推定する機能や、人間が目視確認でマッチング作業をするための機能が提供されます。Mix’n’matchでマッチした結果は、Wikidataに自動的に反映されるようになっています。
図 1 Mix’n’match トップページ
https://mix-n-match.toolforge.org/ (参照2025-12-08)
Mix’n’matchを用いたアニメ分野のマッチング試行
今回は、アニメ分野のコレクションを対象にMix’n’matchを用いたマッチング作業を試行します。
カタログの登録
Mix’n’match でマッチング作業を実施するには、対象のデータセットをMix’n’matchが定義するカタログデータ仕様に従ったカタログデータファイルに変換し、Mix’n’matchにカタログとして登録する必要があります。カタログデータへの変換処理は、メディア芸術データベース・ラボが提供するSPARQLクエリサービスを活用することで、SPARQLで記述されたクエリで実現することができます。
メディア芸術データベースのデータセットからカタログデータ仕様に従ったマッピングを検討し、仕様を整理したものが表 1です。「id」「name」「url」列は、カタログにおいてリソースを識別するための識別子、名前、URLを指定するもので、「MADB ID(schema:identifier)」プロパティ、「タイトル(schema:name)」プロパティ、リソースURLの値としてマッピングします。その他の列は、Wikidata内からマッチする候補を推定するための参考情報を与えるためのものです。「desc」列はMix’n’matchシステムにおいて人間が目視で判断するときに表示される説明文であり、アニメ分野の性質を考慮して「ジャンル(schema:genre)」「開始年月日(schema:startDate)」「終了年月日(schema:endDate)」「制作者名(schema: productionCompany)」の値を結合して生成します。「type」列は、カタログのリソースに対応し得るWikidataのクラスを指定するもので、メディア芸術データベースのクラスに応じて同等の意味を持つWikidataのクラスにマッピングします。例えば、アニメテレビレギュラーシリーズクラスの場合には、Wikidataで「テレビで放映された日本のアニメのシリーズ」と定義されている「テレビアニメシリーズ (Q63952888)」クラスを指定します。「P580」「P582」列は、Wikidataのプロパティに直接対応する値を指定するために任意で設定可能な列であり、リソースを識別するために有用と思われるプロパティを指定します。本試行では「開始年月日(schema:startDate)」「終了年月日(schema:endDate)」を指定します。
| 列 | 値のマッピング仕様 |
|---|---|
| id (必須) | schema:identifier |
| name (必須) | schema:name |
| url | リソースURL |
| desc | schema:genre, schema:startDate, schema:endDate, schema:productionCompany が記録されていれば結合して生成 |
| type | ・class:AnimationTVRegularSeries のインスタンスならば、「Q63952888(テレビアニメシリーズ)」 ・class:AnimationMovieSeries のインスタンスならば、「Q202866(アニメーション映画)」 ・class:AnimationVideoPackageSeries のインスタンスならば「Q220898(OVA)」 |
| P580 (start time) | schema:startDate |
| P582 (end time) | schema:endDate |
表 1 カタログデータへのマッピング仕様
これらのマッピング仕様は、次のようなSPARQLクエリで表現できます。このクエリ結果をCSVファイルに出力することで、Mix’n’matchへ登録するためのカタログデータファイルが作成できます。
PREFIX schema: <https://schema.org/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX ma: <https://mediaarts-db.artmuseums.go.jp/data/property#>
PREFIX class: <https://mediaarts-db.artmuseums.go.jp/data/class#>
SELECT
?id
?name
(
CONCAT(?genre,
IF(BOUND(?startDate),
CONCAT(', ',
?startDate,
IF(BOUND(?endDate), CONCAT("〜", ?endDate), "")),
""),
IF(BOUND(?productionCompany), CONCAT(", ", ?productionCompany) , "")
) as ?desc
)
(?col as ?url)
(
IF(?class = class:AnimationTVRegularSeries, "Q63952888", # テレビアニメシリーズ
IF(?class = class:AnimationMovieSeries, "Q202866", # アニメーション映画
IF(?class = class:AnimationVideoPackageSeries, "Q220898", # OVA
""))
) as ?type
)
(?startDate as ?P580) # 開始日
(?endDate as ?P582) # 終了日
WHERE {
?col a ?class ;
schema:name ?name ;
schema:genre ?genre ;
schema:identifier ?id .
FILTER (LANG(?name) = "")
OPTIONAL {
?col schema:startDate ?startDate .
}
OPTIONAL {
?col schema:endDate ?endDate .
}
OPTIONAL {
?col schema:productionCompany ?productionCompany .
}
VALUES ?class {
class:AnimationTVRegularSeries class:AnimationMovieSeries class:AnimationTVSpecialSeries class:AnimationVideoPackageSeries
}
}
ORDER BY ?id
マッチング
前述のカタログデータをMix’n’matchに登録すると、図 2の画面が表示されます。この画面では、登録したカタログに含まれるリソースのマッチングの状況が次の分類で示されています。
- Fully matched:手動でマッチした、あるいは既にWikidataでリンクされていたリソースの件数
- Preliminarily matched:Mix’n’matchによって推定された候補が存在するリソースの件数
- Not applicable to Wikidata:Wikidataにリンク対象が存在し得ないリソースの件数
- Unmatched:マッチしていないリソースの件数
アニメ分野のコレクションのリソース12,646件のうち、4,064件のリソースが「Preliminarily matched」状態、8,309件が「Unmatched」状態というマッチング結果となっています。つまり、Wikidataのリソースとのリンクを増やすためには、この2つの状態のリソースを「Fully matched」状態にする作業が必要です。「Preliminarily matched」状態のリソースに対しては、推定された候補の正誤を目視で確認して正しい候補を選択するか、手動でWikidataを検索してマッチするリソースを指定することで「Fully matched」状態になります。「Unmatched」状態のリソースに対しては、手動でWikidataを検索してマッチさせるリソースを指定することで「Fully matched」状態になります。Mix’n’matchでは、これらの作業を効率的に行うための画面が提供されています。
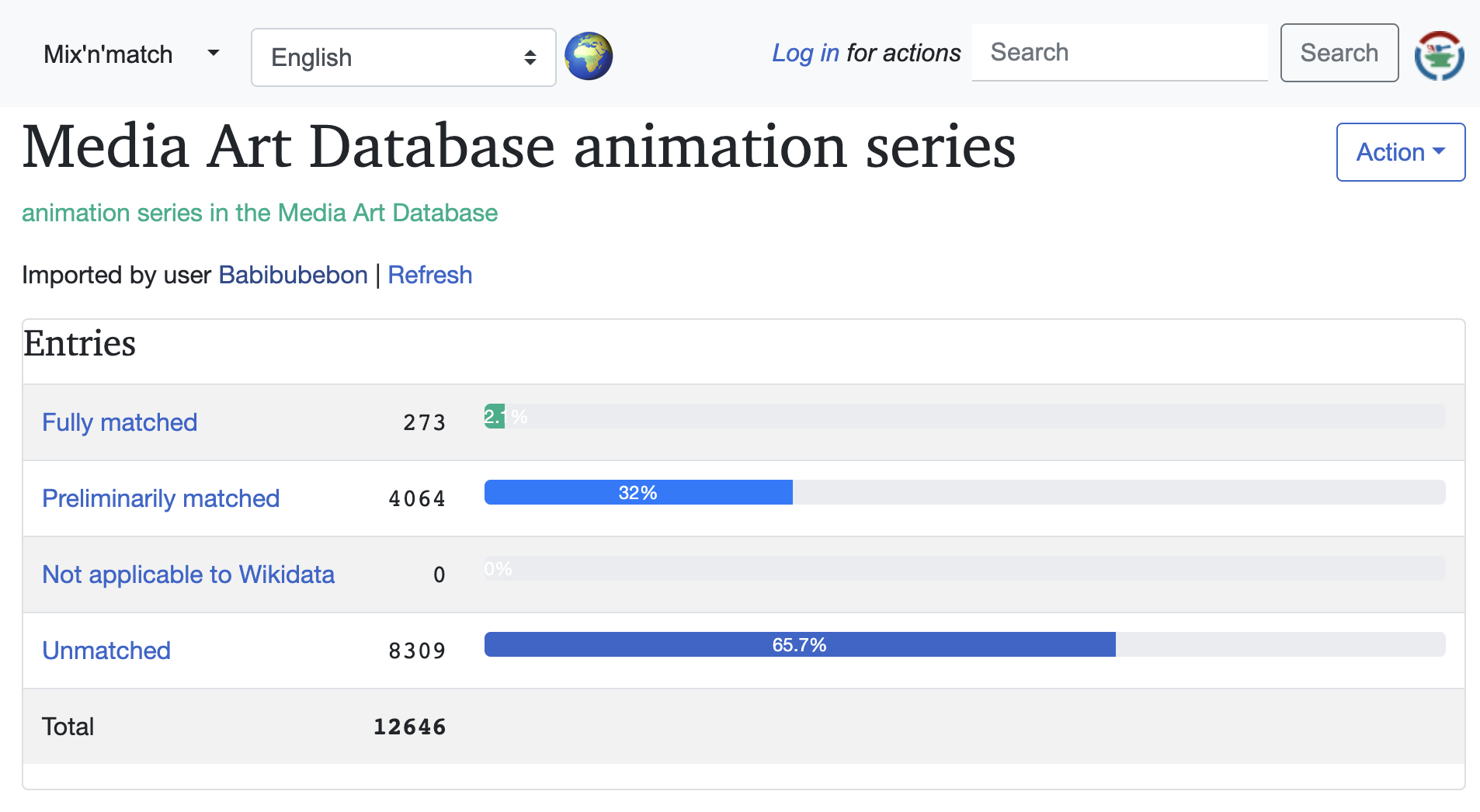
図 2 Mix’n’matchに登録したカタログページ
https://mix-n-match.toolforge.org/#/catalog/6653 (参照 2025-10-13)
図 3は「Preliminarily matched」状態のリソースと推定された候補のリストが表示され、候補の確認作業を行うための画面です。正しい候補だと判断した場合は、「Confirm」をクリックし、その候補を「Fully matched」状態として採用します。誤った候補だと判断した場合は、「Remove」をクリックし、候補から削除します。この作業を繰り返すことでマッチングを進めていきます。この画面にはリソースの名前と説明文が表示されていますが、これらの情報のみで判断が難しい場合は憶測で判断せず、各リンク先のページを参照してより詳しい情報を確認することが重要です。また、アニメ分野においてはごく類似したタイトルで異なるアニメシリーズが公開されることがしばしば存在する、といった分野固有の性質を知っておくことも適切に判断する上で重要です。
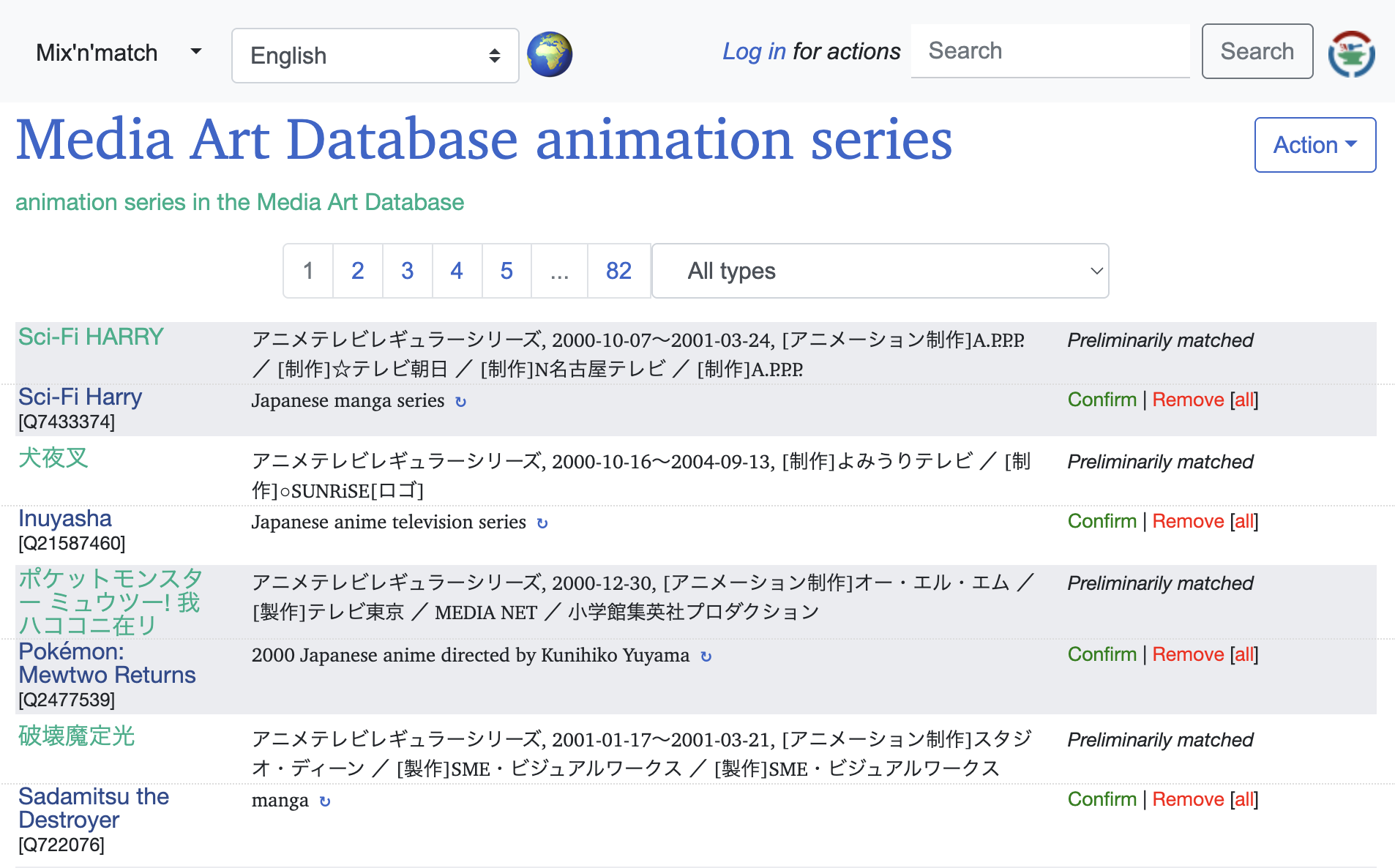
図 3 Preliminarily matchedの作業画面
https://mix-n-match.toolforge.org/#/list/6653/auto (参照 2025-10-13)
図 4は「Unmatched」状態のリソースのリストが表示され、手動でWikidataのリソースを検索しマッチするための画面です。各リソースの下には、WikidataやWikpediaなどを検索するためのリンクが表示されており、これらを参照しながら適切なリソースがWikidataに存在するか探します。見つかった場合には「Set Q」をクリックし、そのリソースのQ番号(WikidataのリソースのID)を入力することで、「Fully matched」状態として採用します。見つからない場合には、「New item」をクリックしてWikidataに新たなリソースを作成します。データとして不正などWikidataに作成すべきでないリソースであった場合には、「N/A」をクリックして「Not applicable to Wikidata」状態にします。
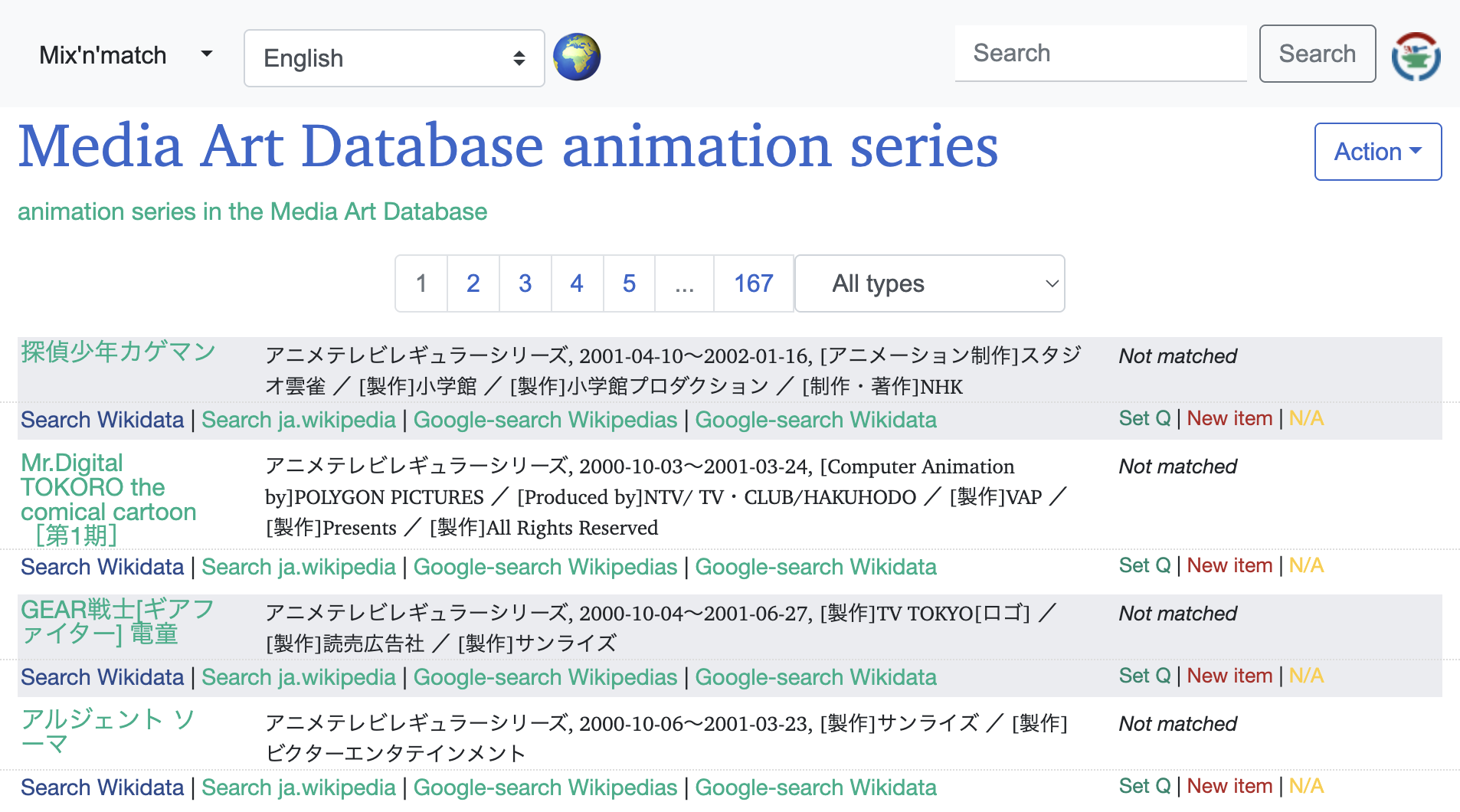
図 4 Unmatchedの作業画面
https://mix-n-match.toolforge.org/#/list/6653/unmatched (参照 2025-10-13)
なお、これらの作業を実行するにはWikimediaアカウントでMix’n’matchにログインしておく必要があります。
おわりに
本レポートでは、メディア芸術データベースとWikidataのリソース間のリンクを拡充する取り組みとして、Mix’n’matchを活用したマッチングの試行について紹介しました。Mix’n’matchは、候補の自動推定機能や人手による確認作業のためのインタフェースを備えており、マッチング作業の効率化および標準化に寄与すると期待されます。さらに、Mix’n’matchに登録されたカタログはWebを通じて世界中に公開され、誰でもマッチング作業に参加することができます。研究者などの専門家だけでなく、各分野のファンの知見も反映されうる点に大きな可能性があります。本レポートではアニメ分野のみを試行しましたが、他の分野にも同様の方法が適用可能であり、このような分散的かつ協働的な仕組みは、増加し続けるデータを抱えるメディア芸術データベースにおいて、マッチング作業のスケーラビリティを確保する有効な手段となり得ます。
一方で、候補の精査には分野固有の知識が要求される場合があり、作業者によってマッチング作業の品質が均一でなくなる可能性があります。リソースの識別に関するガイドラインの整備など、作業者が同じ基準で作業できるようにするための仕組みづくりが求められます。また、候補の自動推定の適合率を向上させることも、作業者による判断そのものを削減するために必要です。
今後は、今回の試行で得られた知見をもとに、継続的な取り組みにすることや、他の分野にも適用範囲を広げることを検討していきます。こうしたWikidataをはじめとするオープンなデータセットとの連携強化を図ることで、メディア芸術データベースが国際的な文脈で再利用されやすくなり、学術研究や教育、さらには一般利用において新たな価値を生み出す基盤となることが期待されます。