



3Dグラフィックスに関係する分野の初学者向けに「3Dグラフィックスの歴史」を解説する本連載。前2回では、ゲームグラフィックスへの3DCGの導入、グラフィックスプロセッサ(GPU: Graphics Processor Unit)の出現、プログラマブルシェーダ技術の急速な発展を追ってきた。今回はDirectX11登場以降の業界の動向と、新たに誕生した「GPGPU」について取り上げていく。
 GPGPUを公式にサポートした世界初のGPU、GeForce 8800GTXを掲げるNVIDIAのチーフサイエンティスト(当時)のデイビット・カーク氏。氏は「GeForceの父」と呼ばれ、NVIDIAのGPGPU注力戦略を指揮したと言われる人物である。CG関連やGPU関連の特許を70以上取得。近年は、世界各国の大学などで講演等を行っている。趣味は自転車とのこと
GPGPUを公式にサポートした世界初のGPU、GeForce 8800GTXを掲げるNVIDIAのチーフサイエンティスト(当時)のデイビット・カーク氏。氏は「GeForceの父」と呼ばれ、NVIDIAのGPGPU注力戦略を指揮したと言われる人物である。CG関連やGPU関連の特許を70以上取得。近年は、世界各国の大学などで講演等を行っている。趣味は自転車とのこと
前回までの流れと今回のテーマ
前回までの流れを完結にまとめると以下のようになる。
第1回 3Dゲームグラフィックスの幕開け
・ゲームグラフィックスに3DCG技術の導入が盛んになる
・3DCG技術を司るプロセッサとして「GPU」が誕生する
・複数のプロセッサメーカーがGPUを独自に好き勝手に機能強化し、互換性の面で混沌となる
・「新たな3Dグラフィックス表現」をGPUの機能としてではなく「GPUで動かせるソフトウェアの形態」として実装していく「プログラマブルシェーダ技術」が誕生する
第2回 プログラマブルシェーダ技術がもたらしたGPUの成長と淘汰
・より高度なシェーダープログラムが実行できるように、とプログラマブルシェーダ技術が急速に進化を遂げる
・プログラマブルシェーダ技術が進化していく流れにおいてGPUの構造は急速に複雑/高度化
・PCだけでなく家庭用ゲーム機にもプログラマブルシェーダ技術が採用に。今やスマートフォンにも採用されるように
・かつては多くの企業がGPUを開発していたが、一部の高度な技術を持ったメーカー以外は手を引くようになる
DirectXの世代でいうと、第1回、第2回でDirectX11世代のGPUまでの進化を見てきたことになる。3回目となる今回は、この後の業界の動向を見ていくことにしたい。
DirectX11以降のDirectXとDirectX12の台頭
DirectX11登場後は、DirectXの進化はスローペースとなっている。2012年にマイクロソフトはDirectX11.1を発表。2013年にはDirectX11.2が、2015年にはDirectX11.3が発表されている。これらはいずれもDirectX11からのマイナーチェンジ版とも言うべきで、細かな機能追加が行われたバージョンという位置づけである。なお、本稿では、このDirectX11.xの細かなバージョンアップ内容の詳細については詳しく触れないものとする。
さて、DirectX11.3が発表された2015年には実はDirectX12も発表されている。バージョン番号こそ「11→12」のメジャーバージョンアップとなるのだが、マイクロソフトは「DirectX12はDirectX11と併存する」と説明したうえでリリースしている。なお、Windows 11が登場となった2021年秋の現時点においても、この「DirectX11と12の併存」は継続中である。
この理由についての説明が必要だろう。
DirectXは、それまでの長いDirectXの進化の歴史のなかで、各メーカーのGPUアーキテクチャの違いを吸収するべく、分厚い「抽象化レイヤー」を実装していた。この分厚い「抽象化レイヤー」が、昨今の高い並列性能を持つマルチコアCPUと超高性能化したGPUとを高速に連動動作させる取り組みにおいて、かなりのオーバーヘッドやボトルネックを発現する要因となってしまったのだ。
そこで、マイクロソフトは、DirectX11.xまでの機能面はそのままに、DirectX11.xとの互換性を捨てつつ、この抽象化レイヤーを極薄化したDirectX 12を開発・発表したわけである。
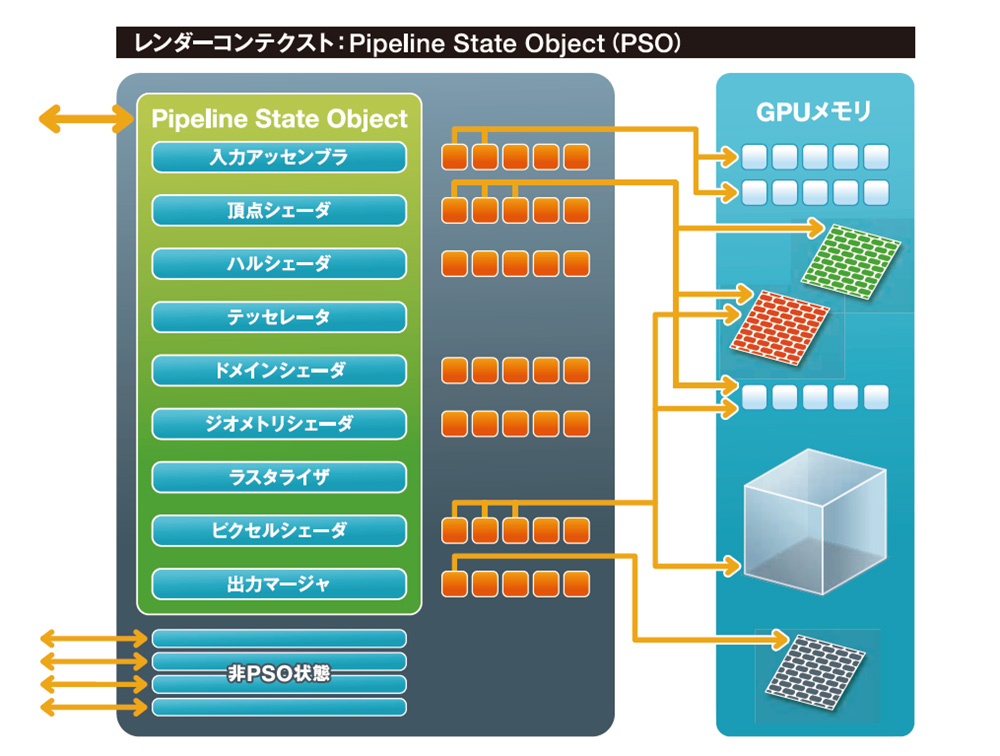 DirectX12のレンダーコンテクスト概念図。DirectX12では図左側の青マスで表されるGPU内部の各機能ブロックの状態取得や設定を、あらかじめ定義していたオブジェクト(緑マス)単位で行えるようになった。その分、オーバーヘッドは劇的に低減されることとなった
DirectX12のレンダーコンテクスト概念図。DirectX12では図左側の青マスで表されるGPU内部の各機能ブロックの状態取得や設定を、あらかじめ定義していたオブジェクト(緑マス)単位で行えるようになった。その分、オーバーヘッドは劇的に低減されることとなった
DirectX11と12を併存させる主な理由は「過去のソフトウェア資産との互換性維持のため」という目的があるにはあるが、それよりもリアルタイム性がそれほど求められないアプリケーションの開発においては抽象化レイヤーが分厚いDirectX11の方が扱いやすいという側面を尊重したためだと言われている。
ところで、この「分厚い抽象化レイヤーの撤廃」という動きは、オープンスタンダードなグラフィックスAPIである「OpenGL」にも波及し、OpenGLの仕様を取り仕切るKhronosグループは、「リアルタイム性に優れたOpenGL」とも言うべき新APIとして「Vulkan」を2016年にリリースしている。
さて、「抽象化レイヤー」を極薄化したDirectX12(やVulkan。以下同)は、たしかにCPUとGPUの高速連携を可能にするソリューションとなったが、はっきり言えば、使いこなしには高度な技術力と知識が求められるようになった。それまではDirectX自体が管理してくれた各種リソースのマネージメントも開発者自身が行わなければならず、やや「素人お断り」の雰囲気がある。
では、逆に、DirectX11との互換性を捨ててまで、なぜこのDirectX12が業界に受け入れられるのか。これについても簡単解説しておこう。
これは、第2回の内容とも深く関係しているのだが、かつてはたくさん存在したGPU開発企業が今や数社になってしまったことが理由のひとつだ。「抽象化すべき対象」の数がそもそも少なくなってしまったと換言してもいいかもしれない。
そして第二に、その少なくなったキープレイヤーとなった数社のGPUが、すべて共通仕様であるプログラマブルシェーダ技術ベースで開発されるようになり、結果、必然的に、その内部アーキテクチャがよく似てきたことも理由に挙げられる。つまり、「それほど抽象化する必要がなくなってきた」というわけである。
アプリケーション(≒ゲーム)の開発者の立場からすると、各種リソースのマネージメントが開発者自身に委ねられることになるDirectX12の取り扱いはたしかに高度だが、実は「その取り扱いのスタイル」はとても「家庭用ゲーム機向けのゲーム開発スタイル」に似ている。つまり、DirectX12のアーキテクチャは、ゲーム開発者にとってはむしろ「とっつきやすさ」になっているといえるのだった。ここが第3の理由として挙げられる。最近のゲームは、家庭用ゲーム機とPCに対して広くリリースされることが多くなっているが、「DirectX12を用いたPCゲーム開発」と「家庭用ゲーム機のゲーム開発」が似通ったことで、各ゲームタイトルをPCと家庭用ゲーム機に対し同時並行開発や相互移植などが行いやすくなったとも言われている。
GPUを汎用目的に活用する「GPGPU」という概念の誕生
本連載の第1回でスポットをあてた1990年代のGPUは、シンプルなベクトル演算器の集合体だった。つまり、シンプルな演算を同時並列に行うことに特化したプロセッサとして誕生したわけである。
しかし、2000年に登場したプログラマブルシェーダ技術によって、これ以降、高度なアルゴリズムやロジックをプログラムすることができる素養を身に付けていくことになる。このあたりの流れは本連載第2回で解説している。
さて、CPUについて目を向けると、CPUは、もともとアルゴリズムやロジックを動かすプロセッサとして誕生している。この処理動作を高速化するために、CPUは世代を改めるごとにより高クロック動作するように進化させられてきた。もちろん、投機実行や分岐予測、依存関係のない命令の同時並列実行(スーパースカラ実行)などの技術も盛り込まれていったが、2000年にCPUが1GHz動作に到達するまでは、高クロック化こそが処理速度の向上の特効薬だった。しかし、2000年以降は高クロック化が鈍化。業界は、次第に「CPUの高性能化」を「マルチコア化」へと舵を切るようになる。そう、高度なアルゴリズムやロジックは、できるだけ並列に実行させて処理速度を稼ぐよう、ソフトウェアパラダイム自体に手を入れるようになっていく。
こうしてそれぞれの進化を俯瞰で見てみると、GPUは進化とともにCPU的な素養を獲得するようになり、逆にCPUはGPU的な能力を獲得するように進化していることがわかる。
さて、プログラマブルシェーダ技術とともに進化していく流れの中で「CPU的な処理系も行えなくもない」プロセッサへ姿を変えたGPUに対し、業界はある仮説を訴えかける。それは「GPUをCG描画だけの専任プロセッサとして使うだけはもったいない」「GPUにCG以外の、汎用の処理系を実行させてみたらどうか」というようなもの。これが「GPUの汎用用途活用」という概念、すなわちGeneral Purpose GPU(GPGPU)である。
 ATI(当時、現AMD)のRadeon HD 4000シリーズのテクニカルデモとして公開された『Froblins』(2008年)。GPGPUによる群集シミュレーションの実装に成功したことがアピールされた
ATI(当時、現AMD)のRadeon HD 4000シリーズのテクニカルデモとして公開された『Froblins』(2008年)。GPGPUによる群集シミュレーションの実装に成功したことがアピールされた
このGPGPUという概念が誕生したタイミングは定かではないが、2004年8月に開催された世界初の「GPGPUに関する研究報告会」として「Workshop on General Purpose Computing on Graphics Processors」がロサンゼルスで開催されており、筆者はこちらを取材したことがある。となれば、この学会開催の前年以前にGPGPUの概念は誕生していたことになる。

 「Workshop on General Purpose Computing on Graphics Processors」の会場の様子。登壇者の発表は「今のGPUってGPGPUには使いにくいよね」という内容がほとんどだった。当時、「GPGPUは絶対クるはず!」と思って熱くなっていた筆者だったが、実際に参加してみたら日本人記者は筆者一人だった
「Workshop on General Purpose Computing on Graphics Processors」の会場の様子。登壇者の発表は「今のGPUってGPGPUには使いにくいよね」という内容がほとんどだった。当時、「GPGPUは絶対クるはず!」と思って熱くなっていた筆者だったが、実際に参加してみたら日本人記者は筆者一人だった
世界の先端スパコンに採用されるようになった‟GP”GPU
このGPGPUという概念に「GPUにとっての新しい市場」を見出したNVIDIAは、2008年、GeForce 8シリーズのリリースとほぼ同時に、独自のGPGPUソフトウェアプラットフォーム「CUDA」を立ち上げ、GPGPUの売り込みをスーパーコンピュータ業界、いわゆるHPC(High Performance Computing)業界に仕掛けていく。
NVIDIAは、CUDA発表以降の新GPUを、GPGPU性能を重視した設計として開発。初代のTeslaコアから、Fermiコア、Keplerコアと、3世代にわたって継続的にリリース。これがHPC業界にも高く評価されることになり、以降、スーパーコンピュータの中核的なプロセッサとして「GPGPU用途」専用で、NVIDIAのGPUが採用されるようになる。日本でも2008年、東京工業大学のスーパーコンピュータ「TSUBAME」が、NVIDIAのGPUベースで構築されることとなり注目を集めた。
GPGPU活用の最先端である各種科学技術計算の現場から切望された64ビット倍精度浮動小数点にも対応したGPUは、2010年にGeForce GTX 480やTESLA C2050(GPGPU専用)として登場。スーパーコンピュータへのNVIDIA製GPU採用はさらに進むこととなり、2010年には、世界最速スパコンTOP10のうち、なんと3台がNVIDIAのGPUベースとなった。
「GPGPUを使うとベクトル計算を圧倒的な速度で並列に行える」という事実は、2010年前後からビッグバンのようにあらゆる業界に広まることとなり、GPGPUの応用が多方面で進むことになるのであった。ここで「とある研究分野」に対し「GPGPUの応用」が、劇的な進化をもたらすことになる。それが「機械学習型AI」という分野だ。
今回はここまでとする。このGPGPUという概念の誕生が、大きくその後のコンピュータパラダイムを変革していくのだが、その話は次回詳しくさせてもらうこととしたい。
次回では、昨今の人工知能ブームが、実は、このGPGPUが起点になっていることなどを解説していく。連載テーマに掲げている「ゲームグラフィックス」というキーワードが今回はほとんど出てきていないが、いずれ軌道修正がなされるはずである。
あわせて読みたい記事
- これまでの5年、これからの5年――ゲームプラットフォームの現在・過去・未来を考える2020年12月21日 更新
- これまでの5年、これからの5年――「VR元年」の終焉から世界同時参加のXRライブエンタメへ2020年10月29日 更新
- 2019年度メディア芸術連携促進事業 研究成果マッピング シンポジウムレポートゲーム分野発表2020年4月24日 更新